 zhibo8 直播吧 - 欧洲杯直播_CCTV-5在线直播|NBA直播
zhibo8 直播吧 - 欧洲杯直播_CCTV-5在线直播|NBA直播【Sports+AI】Kaggle体育比赛预测总结
近期忽而对足球比赛预测萌生了一定的兴趣,遂自行爬取最近两年世界各地几十万场联赛的主流博彩公司赛前的赔率变化的时间序列和比赛当时的对阵双方各项数据以待研究,本质上是希望用AI的方法对赛果进行预测,看有没有些错误定价或庄家诱导的可能,抑或赔率是否能足够反应真实的比赛结果,对此感兴趣的Quant/DS/Kaggler也欢迎交流合作。
为了站在前人的肩膀上瞭望更远,特意上在大数据比赛kaggle平台上调研了体育相关的预测类的比赛、dataset与kernel,其大多都可以在这个网页下找到,这篇文章就是对这些资料的阅读汇总与心得体会的展现。sports | Kaggle
首先说说比赛,几乎能找到的kaggle体育相关比赛都是和篮球相关的,或者说几乎都是和NCAA相关的,最著名的就是Google赞助的每年NCAA男篮和女篮的比赛预测,疯狂三月已过,2019年的比赛也正好刚结束,传送门如下:https://www.kaggle.com/c/mens-machine-learning-competition-2019https://www.kaggle.com/c/womens-machine-learning-competition-2019
不得不说,这两个比赛的数据集还是很详尽的,包含了过去多个赛季的regular season、conference tournament、 NCAA tournament的全部赛果和对阵双方的球队信息与球员名单。根据事后分析,这里面可能比赛类型和球队是否属于某个联盟的binary feature和球队的历史表现的信息是有一定prediction power的。
而具体到每一场比赛,更是有着详尽的记录:包括基础的统计信息:比如每场比赛都有对阵双方的得分、三分球、罚篮、篮板(进攻、防守)、助攻、盖帽、抢断、失误、犯规等,甚至还有每场比赛的详细事件日志。
说到这里大家可能觉得这么丰富的数据,NN这种复杂模型应该能大显身手了。但很可惜,事实上最终根据post出来的winner's solutions,里面几乎绝大部分能用的是简单generalized linear model。而排名靠前的几个选手甚至很多都加入了个人信仰,比如赌某支队会一直力挽狂澜,还有一个哥们是data scientist也常年是篮球狂热爱好者,于是他的取胜之匙就是manually input predictions for as many match-ups as I could given the submission deadline。
大概任何涉及到钱的预测(ncaa的每场比赛都是可以博彩投注的)都不免伴随着很多随机和噪声,这点和金融很像。故而降低variance总是显得比降低bias迫切。此外由于比赛最终的loss与预测概率挂钩,抛开那些用个人远见卓识(也或者只是运气)提高leaderboard排名的,logit模型则尤显得有用武之地,比较好的一个介绍见下:Bradley-Terry Model
这个Bradley Model认为获胜概率  和两个队的水平差有关系,最简单的,队伍j和队伍k在第i场比赛的获胜概率可以这么计算:
和两个队的水平差有关系,最简单的,队伍j和队伍k在第i场比赛的获胜概率可以这么计算:
![\[ \pi_i{(k \quad win)} = \frac{exp(\alpha_i{k} - \alpha_i{j})}{exp(\alpha_i{k} - \alpha_i{j}) + 1} \]](https://yipyia.com/zb_users/upload/2024/02/202402241708714578285491.jpg)
熟悉GLM的朋友都知道,logistic regression其实认为先验分布是二项分布(普通线性回归认为是正态分布),有了这个公式之后,接下来的任务就是估计队伍的水平和计算后验分布(常见的是用MCMC马尔科夫链蒙特卡洛方法)。duythedewey/Kaggle_NCAA_Womens_2019
上面这个winner's solution尝试了更多的prior distribution,比如beta分布,gamma分布等。
当然也不是说完全没有非线性模型与非信仰上分选手的春天,以下两个kernel分别用了LightGBM和NN进行预测:https://www.kaggle.com/c/mens-machine-learning-competition-2019/discussion/89645#latest-517740
之前我们提到,这个比赛给的feature是很全的,这就给大家了充足的feature selection和feature engineering空间,有winner's solution提到进攻效率和防守效率是最有用的特征,也有人说他用了pre-season top25 rankings和point spread提高了模型效果,这些都是有关线性模型的。
此外上面使用NN的选手也总结了他最终只用到的12个特征:
在调研期间恰巧发现NCAA女篮比赛预测的第15名是某知乎著名AI少年部分 @AlexL (部分idea借鉴自Kagglee GM Raddar),于是询问了他的模型思路,几个关键点总结如下:模型用的LightGBM,l1和l2开的很大预测目标函数用的Cauchy不直接预测赛果而是分差Fit isotonic regression
说了这么久篮球最后还是回到我个人更感兴趣的足球吧,虽然没有相关比赛,但Kaggle上相关的数据集还是不少的,比如这些:https://www.kaggle.com/hugomathien/soccerEuropean Soccer Database Supplementaryhttps://www.kaggle.com/martj42/international-football-results-from-1872-to-2017https://www.kaggle.com/karangadiya/fifa19
我个人比较感兴趣的是这个关于赔率时间序列的dataset和其中的一个kernel:https://www.kaggle.com/austro/beat-the-bookie-worldwide-football-datasetReproduction of winning strategy kernel
由于是赔率数据,自然预测结果是为了生成一个可行的投注策略,这个kernel用到的简单判断方法和最终的结果如下: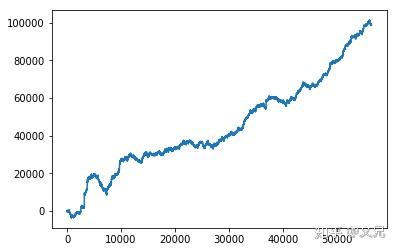
欢迎志同道合者与我私信交流~


版权声明
本文仅代表作者观点,不代表xx立场。
本文系作者授权xx发表,未经许可,不得转载。






作者文章
- 【省145.86元】VIK其他营养_vik 维克 德国VIKpro进口专利高含量槲皮素菠萝蛋白酶胶囊肺部动力保健60粒多少钱-什么值得买 2个月前 (08-18)
- 2024年世界水日:关注饮水卫生,共享健康生活_手机搜狐网 2个月前 (08-18)
- 助力巴黎奥运会 2024年老山击剑公开赛开幕在即_腾讯新闻 2个月前 (08-18)
- 2016年欧洲杯进球集锦(2016年欧洲杯进球集锦天下足球) - 欧洲杯 - web体育 2个月前 (08-18)
- 2024年06月26日 欧洲杯 奥地利VS荷兰 比赛直播_足球直播吧 2个月前 (08-17)